
Google DeepMind готовится представить Gemini 3.0 — модель, которая станет важным моментом в эволюции искусственного интеллекта. Обещания амбициозны:
Учитывая скорость, с которой Google развернул Gemini 2.5 в марте 2025 года, анонс третьей генерации вызывает вопросы: это настоящий технологический прорыв или стратегический маневр для захвата рыночной инициативы?
В этой статье мы разберем, что известно о Gemini 3.0 на основе публично доступных предварительных тестов, какие улучшения ожидаются, как модель выступает в бенчмарках, какие сценарии использования открываются для бизнеса и разработчиков и самое главное — когда модель станет доступна в агрегаторе нейросетей GPTunneL.
По данным нескольких технических обзоров и инсайдерских публикаций, третье поколение Gemini 3.0 продолжает архитектурную линию предыдущих моделей и использует усовершенствованную Mixture-of-Experts-архитектуру: при каждом запросе активируется только часть параметров, что позволяет удерживать высокую производительность при более низких вычислительных затратах и задержке.
Учитывая это, можно также ожидать, что третья версия будет включать усиленный механизм структурированного планирования и самокоррекции в процессе рассуждения, что снижает вероятность галлюцинаций и повышает надежность в профессиональных кейсах.

Модель также сохраняет в массивное контекстное окно в 1 миллион токенов, что эквивалентно примерно 750 000 английских слов или книге на 300 страниц. Google предлагает две конфигурации:
Эта гибкость дает пользователям возможность балансировать между производительностью и бюджетом, выбирая оптимальный вариант под конкретный сценарий.
Новая модель демонстрирует заметный прогресс в областях, которые ранее представляли сложность даже для топовых систем. Разработчики делают акцент на четырех направлениях, где Gemini 3.0 превосходит более ранние версии.
Gemini 3.0 показывает исключительные способности в буквальном и абстрактном рассуждении на бенчмарках Hieroglyph Benchmark и KingBench, что показывает высокий уровень пригодности для задач, требующих нестандартного подхода. Можно ожидать, что модель сможет выполнять ряд сложных задач:
Это особенно полезно в сценариях стратегического планирования, математических доказательств и системного дизайна, где требуется многоэтапная аргументация.
Визуальные возможности Gemini 3.0 пока можно описывать только по аналогии и предварительным наблюдениям: предыдущие версии (1.5 и 2.5) уже умели надёжно разбирать сложные PDF-документы с таблицами, схемами и графиками и извлекать из них структурированные данные — это показывают официальные примеры документ-понимания Gemini. На уровне продукта те же модели уже сейчас используют в Google Sheets, где Gemini умеет анализировать несколько таблиц сразу и по запросу строить диаграммы (столбчатые, линейные, круговые и др.) из табличных данных.
Учитывая этот информационный фон, ранние обзоры и бенчмарки чекпоинтов, которые сообщество связывает с Gemini 3.0 Pro (например, «lithiumflow» в LMArena и разборы его сильной визуальной и табличной логики, разумно ожидать, что финальный релиз Gemini 3.0 сохранит акцент на глубоком анализе сложных документов и диаграмм: корректной реконструкции структуры таблиц, понимании связей между ячейками и переводе визуальных представлений (графики, диаграммы) в осмысленные текстовые описания и аналитические выводы, хотя до официальных спецификаций это остаётся именно обоснованным ожиданием, а не гарантией.
По сообщениям от экспертов в ИИ на Reddit и Twitter, Gemini 3.0 будет способна генерировать более 2 000 строк фронтенд-кода за один запрос, включая полные функциональные модули, адаптивные макеты, анимации и переходы.
В тестах по разработке игр модель продемонстрировала впечатляющие результаты:
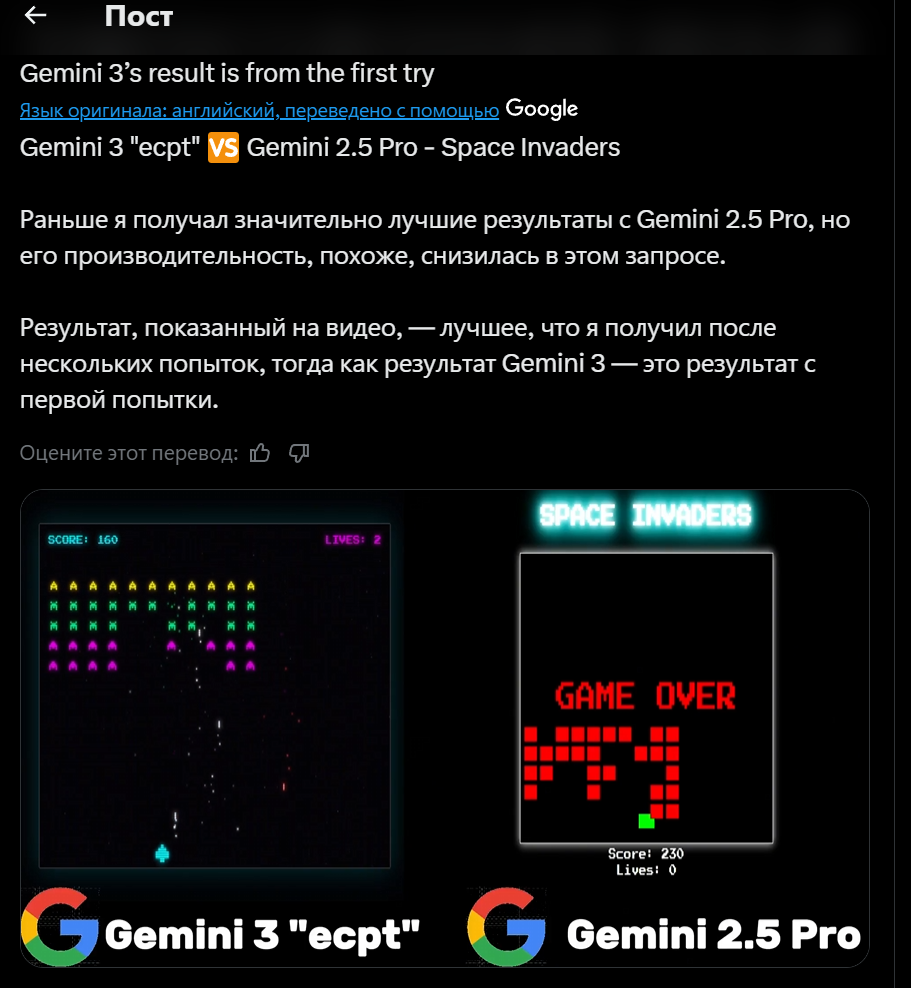

Модель также генерирует SVG-код высокого качества, понимая сложные дизайнерские требования, поддерживая анимации и интерактивные эффекты, а также оптимизируя производительность и размер файлов. По ранним тестам чекпоинта LithiumFlow, который сообщество связывает с Gemini 3.0 Pro, уже видно, что модель уверенно работает с SVG-кодом: в сравнительном тесте на Reddit она даёт более аккуратные и чистые” SVG-изображения (например, пеликана и геймпад PS4), чем Gemini 2.5 Pro и другие модели.
На основе этих кейсов корректнее говорить, что от Gemini 3.0 **обоснованно ожидают** высокое качество SVG-кода для иконок, интерфейсов и сложных иллюстраций, включая поддержку сложной структуры и потенциально анимаций, но детали по оптимизации веса файлов и продвинутым интерактивным эффектам станут ясны только после официального релиза.
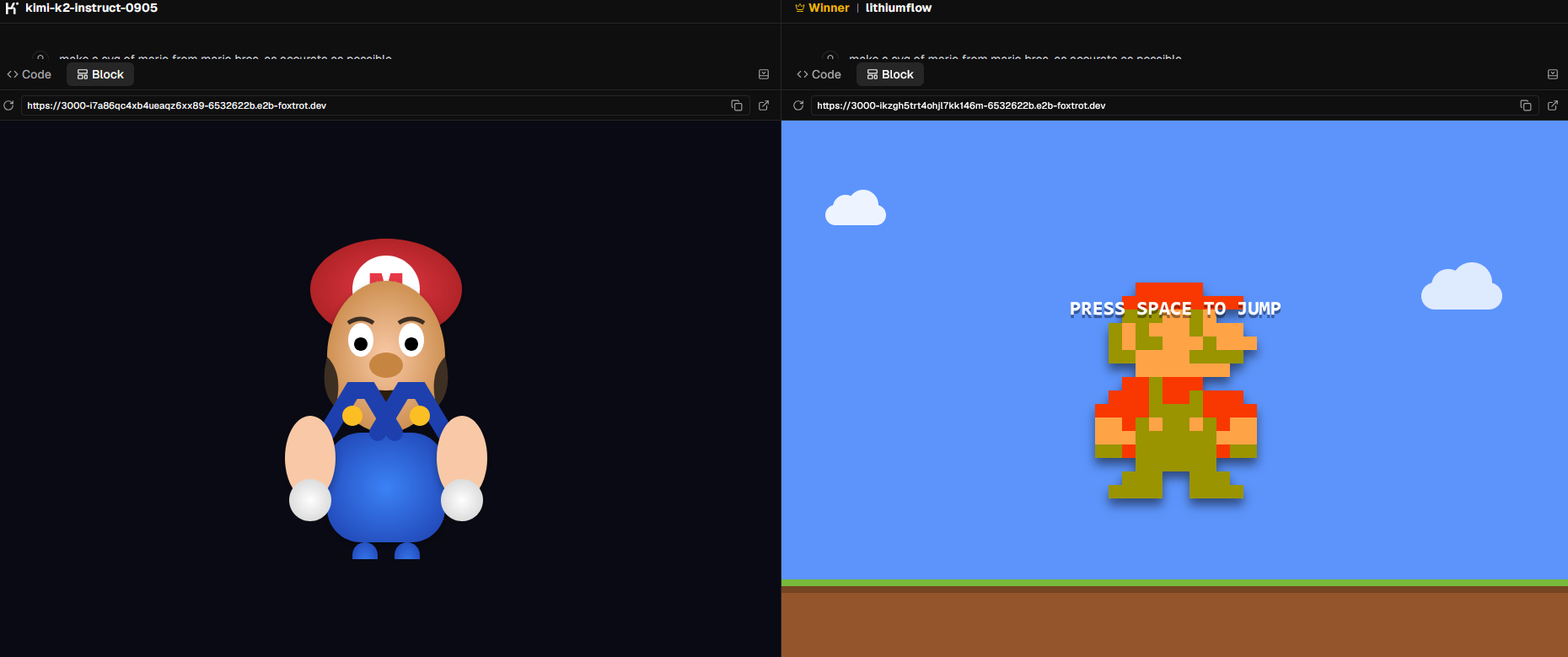
Gemini 3.0 будет нативно мультимодальной моделью, как и ее предыдущая версия — Gemini 2.5 Pro. Это означает, что она спроектирована с самого начала для понимания и генерации контента в нескольких форматах. Модель будет обрабатывать:
Межмодальное рассуждение позволит модели понимать текст в изображениях и связывать его с контекстом, анализировать видеоконтент и генерировать детальные описания, распознавать речь в аудио и синтезировать информацию из нескольких модальностей для предоставления комплексных ответов. Эта способность приблизит Gemini 3.0 к обработке задач, близких к реальным сценариям, а не просто к работе с одномодальной информацией.
Утечки бенчмарков, а также тесты эндпоинта LithiumFlow на LMArena показали превосходство над конкурентами по ключевым метрикам. Два бенчмарка демонстрируют технологическое превосходство модели и ее способность переопределить стандарты производительности в индустрии ИИ.
В Hieroglyph Benchmark, который оценивает креативное решение проблем и латеральное рассуждение, Gemini 3.0 Pro показал существенное улучшение по сравнению с Gemini 2.5. Этот тест измеряет способность модели находить нестандартные решения и работать с абстрактными концепциями, что критично для задач стратегического планирования и инноваций.
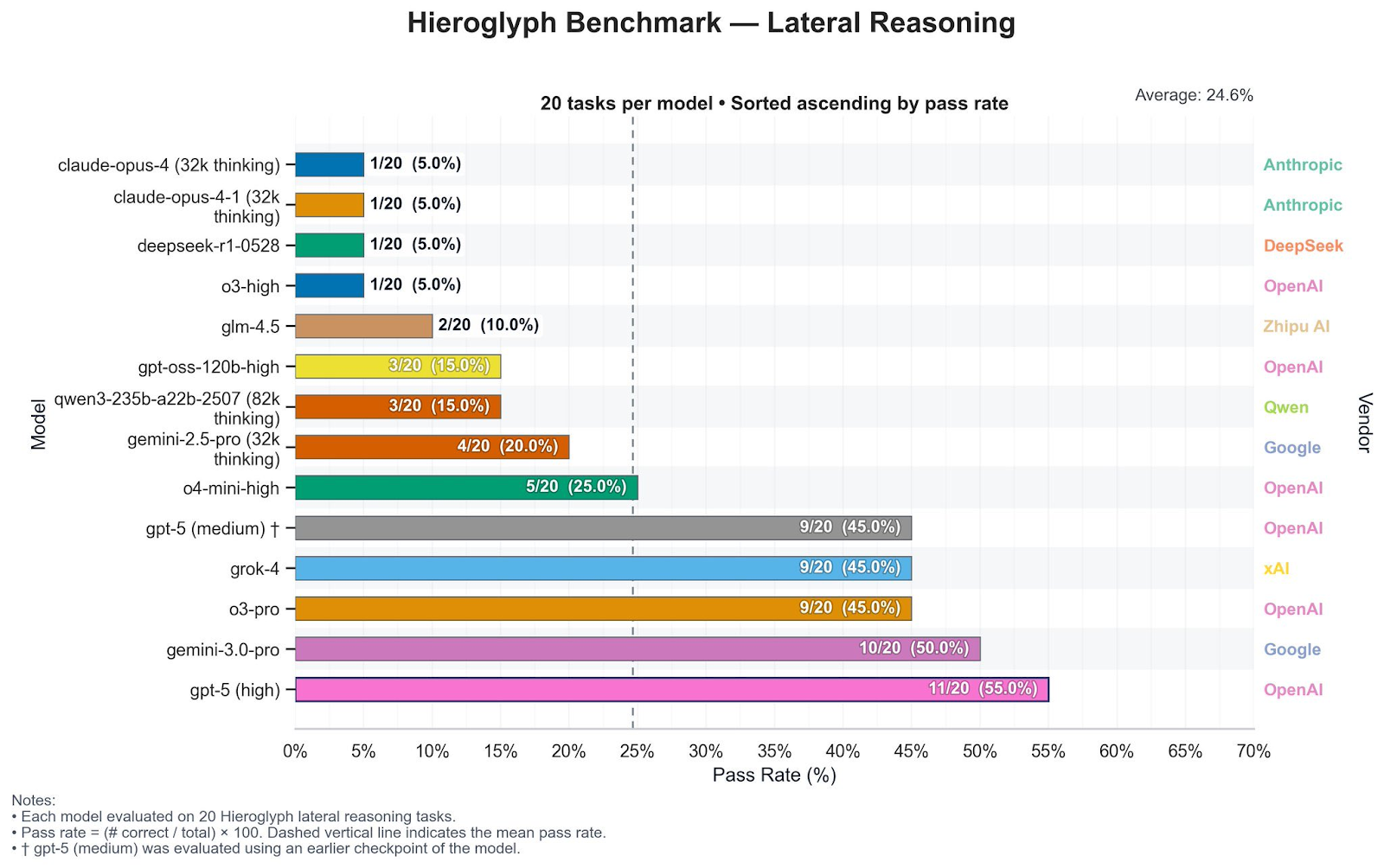
Kingbench Leaderboard фокусируется на реальном рассуждении, кодировании и адаптивности — и здесь Gemini 3.0 Pro занял первое место, опередив Claude 4.5.

Эти результаты не только подтверждают достижения Gemini 3.0, но и сигнализируют о смещении конкурентных акцентов с сырого интеллекта на специализацию, интеграцию и управляемость.
Улучшения в рассуждении, визуальном понимании и мультимодальности открывают широкий спектр прикладных сценариев.
Модель предлагает уникальную ценность в областях, где ранее требовалось участие нескольких специализированных инструментов или значительное ручное вмешательство.
Следует сразу отметить: вышеупомянутые улучшения будут отражены в полной мере только в основном приложении Gemini — в API-версии модели могут быть ограничения, которые станут известны на выходе. Это значит, что такие функции, как, например, анализ видео со звуком и видеорядом, могут быть недоступны у нас.
Поскольку Gemini 3.0 Pro Preview находится на стадии ограниченного тестирования, официальная ценовая стратегия Google также пока не объявлена. При этом, CEO компании Google Сундар Пичаи заявил о выходе до конца 2025 года.
Можно сделать обоснованные прогнозы на основе подхода компании к предыдущим релизам и общих трендов индустрии. Вот, что следует учитывать:
Агрегатор нейросетей GPTunneL уже готовится предоставить доступ к модели. Мы следим за обновлениями и планируем добавить модель на нашу платформу в день выхода. Наши преимущества включают:
Релиз версии Gemini 3.0 свидетельствует о том, что Google приоритизирует скорость выпуска и качество продукта для конкуренции с OpenAI (GPT-5.1) и Anthropic (итерации Claude). Это быстрое соревнование заставит всех других крупных разработчиков ускорить разработку своих инновационных моделей, чтобы соответствовать этому темпу инноваций.



