Anthropic выпустила две модели четвёртого поколения почти одновременно — и впервые разрыв между более дешёвой Sonnet 4.6 и флагманской Opus 4.6 настолько узок, что выбор определяется не качеством в абсолютном смысле, а соответствием конкретной задаче. Обе модели доступны в GPTunneL:
Этот материал показывает, где каждая модель лидирует, как их ценообразование работает в реальных рабочих процессах, и предлагает готовые шаблоны промптов для типовых рабочих процессов. Вы узнаете, когда переплата за Opus оправдана — например, при извлечении данных из документов объёмом в миллион токенов, где Opus 4.6 набирает 76% точности против 18,5% у Sonnet 4.5.
К концу статьи у вас будет система принятия решений для маршрутизации задач между моделями, опирающаяся на бенчмарки, стоимость токенов и проверенные сценарии использования.
Anthropic выпустила Claude Opus 4.6 и Sonnet 4.6 в феврале 2026 года. Обе модели получили адаптивное мышление, контекстное окно на 1М токенов и ограничение вывода в 128k — эти функции доступны в GPTunneL без ограничений.
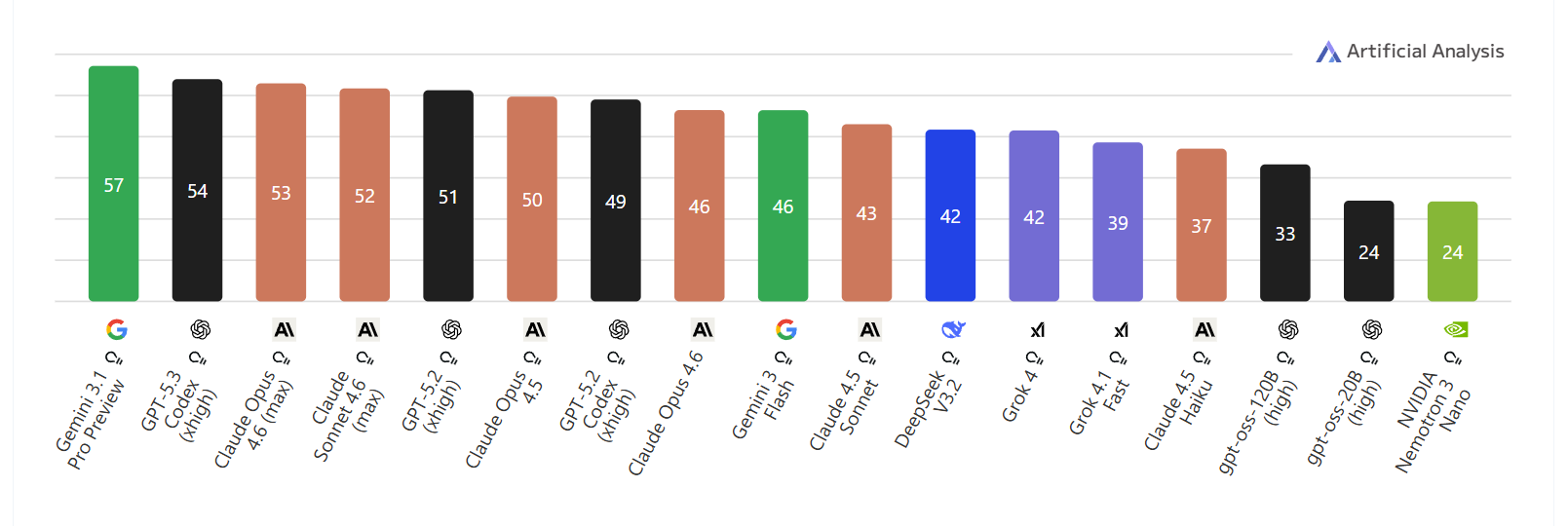
Разрыв между моделями резко сократился. По данным Artificial Analysis Intelligence Index, Claude Sonnet 4.6 набирает 52 балла, а Сlaude Opus 4 6 — 53, то есть разница составляет всего 1 пункт против 7 в предыдущем поколении. Впервые модели Anthropic занимает сразу третье и четвертое места в Intelligence Index — сводном рейтинге по 10 оценкам, охватывающим офисные задачи, написание кода, научное рассуждение.
Раньше разработчики выбирали между качеством и стоимостью; теперь выбор определяется задачами. Sonnet 4.6 подходит для рабочих процессов, где работа с файлами и большим количеством обрабатываемого контекста в день делают разницу в стоимости токена существенной.
Opus подходит для задач, где пропущенная деталь в миллионе токенов текста влечёт реальные последствия — договоры, отчёты о соответствии требованиям, научные исследования. Представив Claude Sonnet 4.6, Anthropic позиционирует его как прямое обновление Sonnet 4.5 с минимальными изменениями промптов, тогда как Opus сохраняет роль флагмана для задач с максимальной глубиной рассуждения.
Чтобы понять, как модели соотносятся технически, полезно начать со справочной таблицы ключевых характеристик. Это позволяет увидеть, где параметры идентичны, а где проявляются различия.
Параметр | Claude Sonnet 4.6 | Claude Opus 4.6 |
Контекстное окно | 1М токенов | 1М токенов |
Максимальное количество выходных токенов | 128k | 128k |
Стоимость контекста (за 1К токенов) в GPTunneL | 1.2 ₽ | 15 ₽ |
Стоимость генерации (за 1К токенов) в GPTunneL | 6 ₽ | 75 ₽ |
Уровни усилий адаптивного мышления | Нулевой, низкий, средний, глубокий | Нулевой, низкий, средний, глубокий |
Доступность |
Обе модели поддерживают одинаковые уровни усилий — низкий, средний, глубокий по умолчанию и максимальный — что позволяет разработчикам напрямую управлять глубиной рассуждения модели перед ответом и таким образом контролировать потребление токенов.
Контекстное окно на 1М токенов доступно для обеих моделей, что позволяет модели анализировать целые кодовые базы, договоры или научные статьи в одном чате.
Практический совет: протестируйте сценарий с длинным контекстом на обеих моделях, чтобы увидеть, оправдывает ли точность Opus дополнительные затраты в вашем конкретном случае.
Бенчмарки рассказывают неожиданную историю. Более дешёвая модель побеждает на самых практичных задачах — агентное управление компьютером, написание кода, офисная работа. Флагман лидирует там, где важны глубина рассуждения и точность работы с длинным контекстом: многодисциплинарные задачи, извлечение данных из миллионов токенов, юридический анализ.
Бенчмарк | Что измеряет | Балл Sonnet 4.6 | Балл Opus 4.6 | Победитель |
GDPval-AA Elo | Офисные задачи реального мира: презентации, анализ данных, создание отчетов | 1633 | 1606 | Sonnet 4.6 |
SWE-bench Verified | Разработка программного обеспечения: исправление багов и добавление функций | 79,6% | 80,8% | Opus 4.6 |
TerminalBench | Написание кода и работа с терминалом | 53% | 46% | Sonnet 4.6 |
MRCR v2 8-needle 1M | Извлечение данных из контекста объёмом 1М токенов | 18,5% (Sonnet 4.5) | 76% | Opus 4.6 |
Humanity's Last Exam | Многодисциплинарное рассуждение высокой сложности | 33.2% | 40.0% | Opus 4.6 |
Vending-Bench Arena | Долгосрочное бизнес-планирование для проекта — торгового автомата | ~$5 700 прибыли | — | Sonnet 4.6 |
BigLaw Bench | Юридическое рассуждение и точность | — | 90,2% | Opus 4.6 |
Эти данные, взятые из официальных анонс двух моделей, показывают паттерн:
Для команд и пользователей, использующих Claude 4.6 для работы, это означает гибридную маршрутизацию: короткие структурированные задачи направляются в Sonnet с низким или средним уровнем усилий при рассуждении; сложные или критически важные подзадачи переключаются на Opus с глубоким уровнем.
На офисных задачах в бенчмарке GDPval-AA Claude Sonnet набирает 1633 против 1606 у Claude Opus ИИ, в том числе лидирует в финансовом анализе — 63,3% против 60,1%. Это неожиданный результат: более дешёвая модель превосходит флагман на задачах реального мира, которые Anthropic позиционирует как ключевые для пользователей.
Результат Claude на OSWorld вырос с 14,9% в октябре 2024 года у Sonnet 3.5 до 72,5% у Sonnet 4.6 — пятикратное улучшение за 16 месяцев. Это показывает, что каждое поколение существенно повышает надёжность управления компьютером, превращая экспериментальную функцию в производственную возможность.
В ходе раннего тестирования Claude Code пользователи предпочитали Sonnet 4.6 модели Sonnet 4.5 примерно в 70% случаев, а Opus 4.5 — в 59% случаев. Программисты отмечали меньше галлюцинаций, более точное следование инструкциям и меньшую склонность к «лени» — когда модель пропускает шаги или выдаёт неполный результат. Sonnet 4.6 требует минимальных правок промптов, а в GPTunneL модель стоит столько же, сколько и
В бенчмарке MRCR v2, который тестирует возможности моделей ИИ при работе с контекстом на 1М токенов, Claude Opus 6 набирает 76% против 18,5% у Sonnet 4.5 — разрыв, который важен, когда в запросе содержатся текст договоры, большие фрагменты кода или материалы для исследований. Компании в регулируемых отраслях регулярно анализируют наборы документов такого масштаба, и пропущенный пункт договора может повлечь юридические последствия или финансовые убытки.
Opus 4.6 лидирует на Humanity's Last Exam — сложном тесте многодисциплинарного рассуждения. Модель демонстрирует почти двукратное улучшение по сравнению с Opus 4.5 на тестах по гуманитарным наукам, математике, вычислительной биологии, структурной биологии и органической химии.
Практическое правило: если задача требует извлечь конкретную деталь, спрятанную в огромном документе, или рассуждать над новой задачей — Opus оправдывает ценовую надбавку. Если задача повторяется сотни раз в день и требует надёжного следования инструкциям без абсолютной точности извлечения данных — Sonnet обеспечивает близкое качество при доле затрат.
Полный прогон Artificial Analysis Intelligence Index для Sonnet 4.6 обошёлся в $2 088 против $733 для Sonnet 4.5 — трёхкратный рост при одинаковой стоимости токенов, обусловленный интенсивным потреблением токенов на сложных задачах рассуждения.
Opus 4.6 прошёл тот же индекс за $2 486, что делает Sonnet 4.6 лишь на 16% дешевле при нагрузках при глубоких рассуждениях. Это означает, что разумный подход — направлять короткие структурированные задачи в Sonnet с низким уровнем усилий, а на сложные или критически важные подзадачи переключаться на Opus. Такая гибридная маршрутизация контролирует затраты, не жертвуя качеством там, где оно важно.
Управление уровнями усилий — это реальный инструмент контроля затрат. Установка среднего усилия для рутинных задач форматирования или извлечения данных и высокого только для сложных задач рассуждения может значительно сократить расходы на токены без смены модели. Anthropic Sonnet 4.6 позволяет настраивать уровень усилий для каждого запроса, что даёт вам гибкость в балансировке качества и стоимости.
Вместо того чтобы выбирать модель один раз и применять везде, рассматривайте выбор как задачу маршрутизации: что конкретно требует эта задача? Глубину рассуждения, надёжность при большом объёме, точность извлечения данных из длинного контекста, скорость и стоимость при масштабировании — каждая из этих характеристик указывает на разные модели.
Сценарий использования | Рекомендуемая модель | Почему | На что обратить внимание |
Написание кода | Sonnet 4.6 | Лидирует на TerminalBench (53% против 46%), почти не уступает на SWE-bench, стоит на 40% меньше | Установите средний уровень усилий для итеративных циклов, чтобы контролировать затраты |
Анализ длинных документов (договоры, исследования, кодовые базы) | Opus 4.6 | 76% на MRCR v2 с 8 иглами в 1М токенов; извлекает скрытые детали надёжнее | Используйте контекстное окно 1М токенов в учитывайте повышенную стоимость при анализе больших запросов |
Юридические задачи и задачи соответствия требованиям | Opus 4.6 | 90,2% на BigLaw Bench; высшая точность среди моделей Claude в Harvey | Неверный ответ влечёт последующие издержки — надбавка Opus окупается за счёт сокращения времени проверки |
Финансовое моделирование и работа с таблицами | Sonnet 4.6 | 63,3% на бенчмаре для финансового анализа GDPval-AA; лидирует среди всех моделей | Для сложных многошаговых моделей рассмотрите Opus с глубокими рассуждениями |
Каждодневные вопросы к ИИ | Sonnet 4.6 | Улучшенное следование инструкциям, меньше галлюцинаций, прямое обновление Sonnet 4.5 | Минимальные изменения промптов при миграции с 4.5 |
Многошаговое бизнес-планирование | Sonnet 4.6 | ~$5 700 прибыли на Vending-Bench против ~$2 100 у Sonnet 4.5 — почти 3x | Контекстное окно 1М токенов и контекстная компактизация (бета) для длительных сессий |
Научное или многодисциплинарное рассуждение | Opus 4.6 | Лидирует на Humanity's Last Exam; почти 2x улучшение на биологии и химии | Используйте глубокий уровень усилий для сложных задач |
Эта таблица — отправная точка, а не жёсткое правило. Реальные рабочие процессы часто требуют гибридного подхода: Sonnet для генерации контента и анализа данных, Opus для финального прохода на критически важных подзадачах. Самый быстрый способ калибровать маршрутизацию — запустить типичный промпт на обеих моделях в GPTunneL, сравнить результаты напрямую и увидеть, оправдывает ли улучшение Opus дополнительные затраты в вашем конкретном случае.
Эти шаблоны — отправные точки, а не готовые промпты. Адаптируйте роль, формат вывода и ограничения под свой конкретный контекст. Каждый шаблон содержит рекомендуемую модель и уровень усилий, обеспечивающий баланс качества и стоимости токенов для данного типа задач.
Шаблоны промптов полезны, когда они привязаны к реальным рабочим процессам. Ниже представлены готовые отправные точки для маркетинга, продаж, аналитики и написания кода — с указанием, какая модель и какой уровень усилий обеспечивают лучшее соотношение качества и стоимости для каждого сценария. Все шаблоны проверены на обеих моделях поколения 4.6 и откалиброваны под их возможности.
Рекомендуем для этой задачи: Claude Sonnet 4.6
Почему: высокое качество следования инструкциям при меньших затратах; маркетинговые тексты создаются итеративно, а не за один подход, поэтому Sonnet с средним усилием обеспечивает достаточное качество для черновиков без затрат Opus.
Шаблон: «Ты — старший копирайтер. Напиши [3 варианта рекламы / раздел лендинга / тест строк темы письма] для [название продукта]. Целевая аудитория: [описание]. Тон: [лаконичный / разговорный / авторитетный]. Формат: [маркированный список / короткие абзацы / таблица]. Ограничения: без жаргона, максимум [количество слов]. Сопроводи каждый вариант кратким обоснованием».
Для анализа рекламных кампаний — разбора данных об эффективности по каналам и подготовки рекомендаций — Sonnet 4.6 в режиме глубокого рассуждения хорошо справляется с многошаговым рассуждением без затрат на Opus. Это можно встроить в агентный цикл: один вызов генерирует варианты, следующий оценивает их по критериям — например, соответствие тону бренда, ясность призыва к действию, отсутствие жаргона — последний выбирает победителя на основе балльной системы. Весь цикл выполняется в рамках одной сессии Claude Code с использованием Sonnet, что позволяет команде получить готовый набор вариантов с обоснованием выбора без ручной оценки.
Рекомендуем для этой задачи: Claude Sonnet 4.6
Почему: работа с исходящими продажами предполагает большой объём; улучшенное следование инструкциям Sonnet 4.6 по сравнению с 4.5 снижает потребность в ручной правке, а возможность включить режим рассуждений обеспечивает персонализацию без переплаты за Opus.
Шаблон: «Ты — B2B-стратег по продажам. На основе следующего профиля компании [вставить данные] напиши персонализированное письмо для исходящего контакта с [должность/роль]. Сошлись на [последние новости / продукт / проблему компании]. Включи: тему письма, вступительный крючок, ценностное предложение, связанное с [конкретной болевой точкой], и единственный чёткий призыв к действию. Максимум 150 слов. Без шаблонных фраз».
Рекомендуем для этой задачи: Claude Opus 4.6
Почему: Opus лидирует на Humanity's Last Exam и извлекает точные детали из больших наборов документов с меньшим отклонением; для задач, где пропущенная деталь влечёт реальные последствия, Opus оправдывает затраты.
Шаблон: «Ты — старший аналитик. Я предоставлю [набор документов / научную статью]. Задача: [обобщить ключевые выводы / выявить противоречия / извлечь все упоминания X / сравнить методологию по источникам]. Вывод: структурированный отчёт с разделами [выводы, доказательства, пробелы, рекомендации]. Для каждого утверждения указывай источник и страницу/раздел».
Промпт для финансового анализа может включать конкретные требования к формату: «Вывод: таблица с колонками [метрика, значение Q1, значение Q2, изменение %, интерпретация]. После таблицы — абзац с ключевыми рисками, выявленными в сносках».
Рекомендуемая модель: Sonnet 4.6 — для написания кода и исправления ошибок; Opus 4.6 — для архитектурных решений, миграций и незнакомых кодовых баз.
Sonnet 4.6 лидирует среди всех моделей на TerminalBench 2.0 для написания кода — 53% против 46% у Opus — и почти не уступает Opus на SWE-bench Verified: 79,6% против 80,8%. При выполнении задач программирования, когда задача выполняется десятки раз в день, Sonnet обеспечивает близкое качество при доле затрат.
Шаблон (Sonnet): «Ты — старший инженер-программист. Вот фрагмент кода: [вставить или прикрепить]. Задача: [исправить ошибку в X / добавить функцию Y / рефакторить Z согласно спецификации]. Шаги: 1) Определи первопричину. 2) Перечисли строки для изменения. 3) Внеси изменения с комментариями. 4) Напиши тест. Вывод: в формате diff. Отметь все изменения».
Шаблон (Opus): «Ты — ведущий инженер, проверяющий план миграции. Дано: [краткое описание кодовой базы или полный контекст]. Оцени: [предложенную архитектуру / стратегию миграции]. Вывод: риски, зависимости, поэтапный план и блокеры. Конкретно укажи, какие модули затронуты и в каком порядке».
При ситуациях, где неверное решение влечёт дни работы, Opus оправдывает затраты за счёт снижения риска архитектурных ошибок.
Самый быстрый способ определить, какая модель подходит для вашей задачи, — запустить обе на одном промпте и сравнить результаты напрямую. GPTunnel позволяет вставить один промпт, выбрать Claude Sonnet 4.6 и Opus 4.6 для параллельного сравнения и увидеть оба ответа одновременно — без настройки API, без написания кода, без переключения между вкладками.
Это особенно полезно при калибровке шаблонов промптов. Отправьте промпт в GPTunneL, сравните, как каждая модель интерпретирует инструкции. Затем доработайте промпт — уточните роль, добавьте ограничения, измените формат вывода — и запустите снова. После двух-трёх итераций вы увидите паттерн: если обе модели дают близкие результаты, Sonnet — правильный выбор; если Opus стабильно лучше справляется с извлечением деталей или рассуждением — затраты оправданы.
Типичные сигналы, что Opus стоит своих денег:
Типичные сигналы, что Sonnet — правильный выбор: обе модели дают результаты сопоставимого качества, но Sonnet быстрее, а эту задачу вы будете выполнять постоянно.
Поколение 4.6 смещает вопрос выбора модели с «качество против стоимости» к «маршрутизации задач» — потому что Sonnet теперь сопоставим с Opus на большинстве практических задач. Для команд, запускающих много проектов, изменился расчёт затрат: Sonnet 4.6 обеспечивает производительность, близкую к Opus, на агентных задачах при сниженной базовой ставке, что существенно накапливается при постоянном использовании.
GPTunneL меняет подход к выбору модели: вместо одной модели для всех задач у вас есть разные модели семейства Claude, а также еще 100 других моделей. Это позволяет проверять разные гипотезы, а также контролировать затраты, не жертвуя качеством там, где оно важно, и получать лучшее соотношение производительности и стоимости для каждого типа задач.