
Что такое мультимодальный ИИ? Это парадигма, которая объединяет несколько типов данных в единой системе. Вместо того чтобы анализировать только текст или изображения, современные мультимодальные модели ИИ в GPTunneL обрабатывают текст, изображения, код, таблицы или даже файлы одновременно, создавая более полное понимание информации.
Эта интеграция разных типов входных данных принципиально отличается от традиционного подхода, когда отдельные нейросети решали задачи в своих областях. Мультимодальный ИИ открывает двери для вариантов использования, которые раньше были невозможны. Например:
Кстати, согласно исследованию HubSpot за 2024 год, 71% маркетологов, использующих генеративный ИИ для создания контента, говорят, что этот контент показывает результаты лучше, чем контент без ИИ. Хотя в исследовании не указывается тип ИИ, можно с уверенностью сказать — мультимодальные нейросети меняют наши рабочие процессы.
В этой статье мы рассказываем, какой ИИ можно назвать мультимодальным, показываем, какие возможности доступны у моделей в GPTunneL, а также даем примеры использования и готовые инструменты.
Мультимодальный ИИ объединяет текст, изображения и аудио, чтобы устранить двусмысленность и улучшить принятие решений в реальном времени. Реальные мультимодальный ИИ примеры включают анализ описаний и изображений продуктов, веб-разработку на основе скриншота, . Основная техническая задача — согласование различных форматов данных и снижение вычислительных затрат при сохранении точности.
Понимание того, что такое мультимодальные системы в ИИ, — это ключ к раскрытию их потенциала. Мультимодальный ИИ интегрирует входные данные из разных источников:
Многоканальные нейросети изучают взаимосвязи между ними с помощью фреймворков глубокого обучения, таких как трансформеры и сверточные нейронные сети. В это же время, традиционные системы ИИ преуспевают лишь в одной задаче: языковая модель предсказывает текст, а модель компьютерного зрения размечает изображения.
Модели мультимодального ИИ задаются принципиально иными вопросами:
Этот переход от одноканального к многоканальному восприятию отражает то, как люди на самом деле понимают мир — мы не отделяем зрение от слуха или контекст от наблюдения. Когда вы смотрите фильм, вы одновременно видите актеров, слышите диалог и музыку, читаете субтитры, и все эти потоки информации складываются в единое впечатление. Мультимодальные ИИ модели работают по тому же принципу.
Чтобы сравнить возможности анализа у разных ИИ, предлагаем провести эксперимент:


Вы можете провести собственные тесты с другими моделями в GPTunneL, чтобы понять их возможности на практике. Мультимодальный ИИ сокращает количество ошибок, ускоряет рабочие процессы и позволяет системам справляться с двусмысленностью, которую одномодальные модели полностью упускают.
Это создает огромную бизнес-ценность — от повышения точности анализа данных до ускорения производственных процессов и улучшения клиентского сервиса.
Чтобы понять, как мультимодальная LLM достигает такого глубокого понимания, важно проследить путь данных от момента ввода до принятия финального решения. Этот процесс состоит из пяти ключевых этапов, и каждый решает свою специфическую задачу:
После сбора каждая модальность проходит специализированное кодирование. Приведем пример с тремя типами данных:
Согласование гарантирует, что данные из разных модальностей относятся к одному и тому же моменту или сущности. На этом этапе очень важна формулировка промпта.
Например, мы дали модели ChatGPT-5 запрос, прикрепив к нему графики из отчета DataReportal, показывающие самые популярные соцсети в мире:
«Проанализируй приложенные графики из DataReportal («Global social media statistics») и опиши:
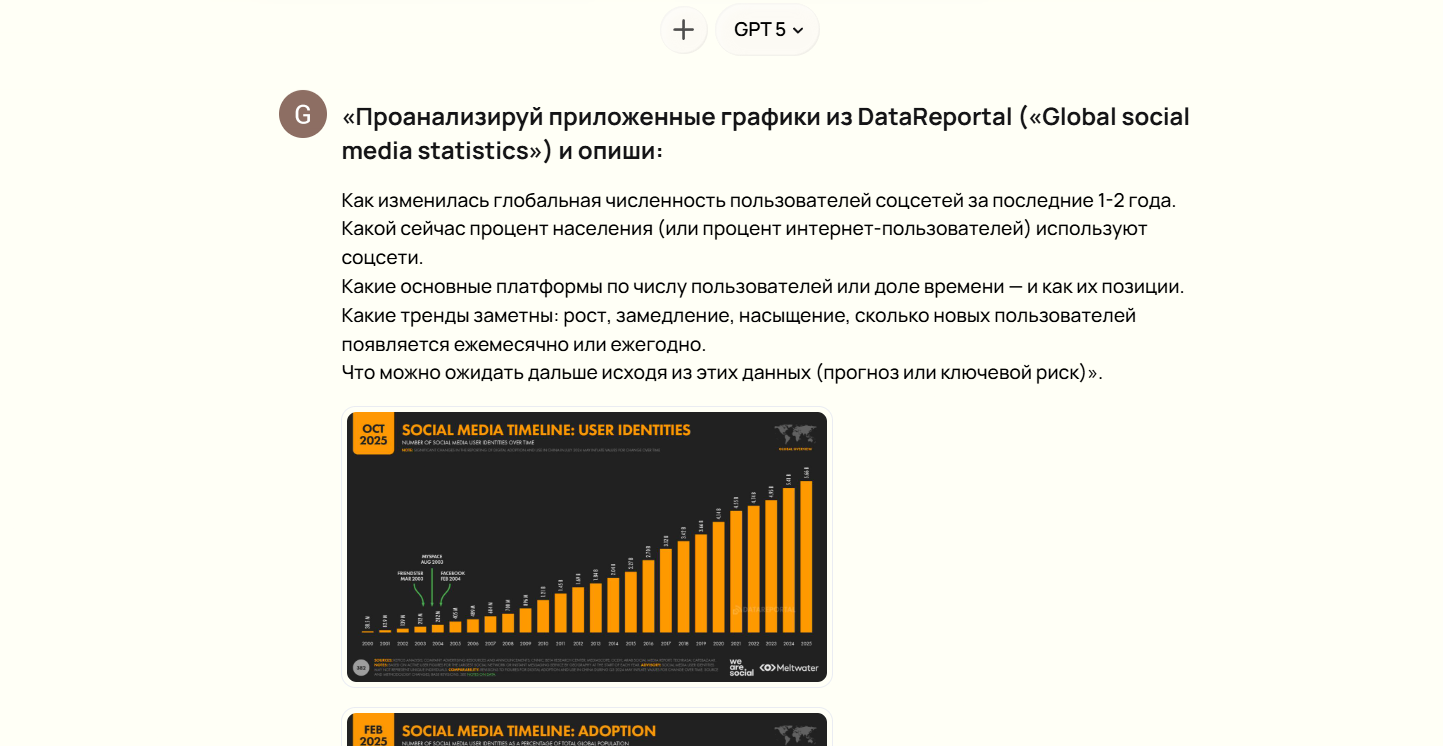
Инструкции, приведенные в нашем чате с моделью, дают четкие указания ИИ, что искать в приложенных графиках. В результате модель дала точный разбор лидеров, извлекла числовые данные по пользователям и рассчитала тренды по использованию соцсетей. Без конкретики в запросе ИИ может неправильно связать части разных потоков данных, что приведёт к ошибочным выводам.
Когда признаки извлечены и согласованы, они поступают на слой слияния — место, где происходит финальное объединение всех данных. Существуют разные стратегии слияния, каждая со своими преимуществами:
Механизмы внимания позволяют модели фокусироваться на релевантных частях каждой модальности. Так, мы дали модели Claude 4.5 Sonnet промпт для анализа изображения кота с указанием неправильного контекста:
«На этом изображении показана собака породы лабрадор в парке. Опиши, что ты видишь на картинке и какое животное на ней изображено».

Посмотрите полный ответ ИИ в нашем чате. Модель корректно определила, что на изображении находится кот, а не собака, и придала больший вес контенту на самой картинке, чем текст. Это показывает, что передовые мультимодальные ИИ модели умеют обращать внимание на важные детали, а не тратить лишнее время на анализ неверной информации.
Чтобы нейросеть обращала внимание на нужные элементы и не путалась, вместе с механизмами внимания применяется мультимодальное обучение в ИИ. Оно включает разметку данных людьми при тренировке, чтобы модель научилась понимать, какие комбинации имеют какое значение. Таким образом, нейросеть «запоминает», чем стол отличается, например, от скамейки.
После завершения обучения мультимодальная ИИ модель готова работать с новыми данными. Вот, как выглядит процесс генерации ответа:
Такая архитектура делает мультимодальные агенты гибкими и эффективными в реальных условиях. Теория становится гораздо понятнее, когда мы видим, как мультимодальные ИИ системы решают конкретные задачи.
GPTunneL предлагает анализ текста, расшифровок сценария видео, файлов, кода и изображений. Анализ самих видео и аудио пока не входит в список доступных функций при работе с LLM в чатах. С учетом этого предлагаем ознакомиться с примерами использования мультимодального ИИ для работы и творчества.
Маркетологи и креативные команды используют мультимодальный искусственный интеллект для ускорения рабочих процессов.

Пример запроса: загрузите серию изображений продукта в чат с Claude 4.5 Sonnet и таблицу с профилями целевой аудитории, а затем попросите нейросеть:
«На основе этого сгенерируй пять уникальных вариантов рекламного текста. Каждый текст должен быть нацелен на отдельный сегмент аудитории из таблицы. К каждому варианту добавь короткие рекомендации для дизайнера по визуальному оформлению».
Система анализирует визуальные элементы продукта
Потом она сопоставляет их с требованиями бренда из промпта и адаптирует сообщение под демографические данные аудитории. Посмотрите полный ответ модели в этом чате.
Мультимодальные модели кардинально ускоряют переход от идеи к реализации. Дизайнеры и разработчики могут превращать визуальные концепции в код за считаные минуты.

Пример запроса: загрузите изображение наброска веб-страницы (сделанного от руки или в графическом редакторе) и напишите в чате с GPT-5 Codex:
«Преобразуй этот макет в работающий HTML и CSS код. Используй семантические теги и обеспечь базовую адаптивность для мобильных устройств».
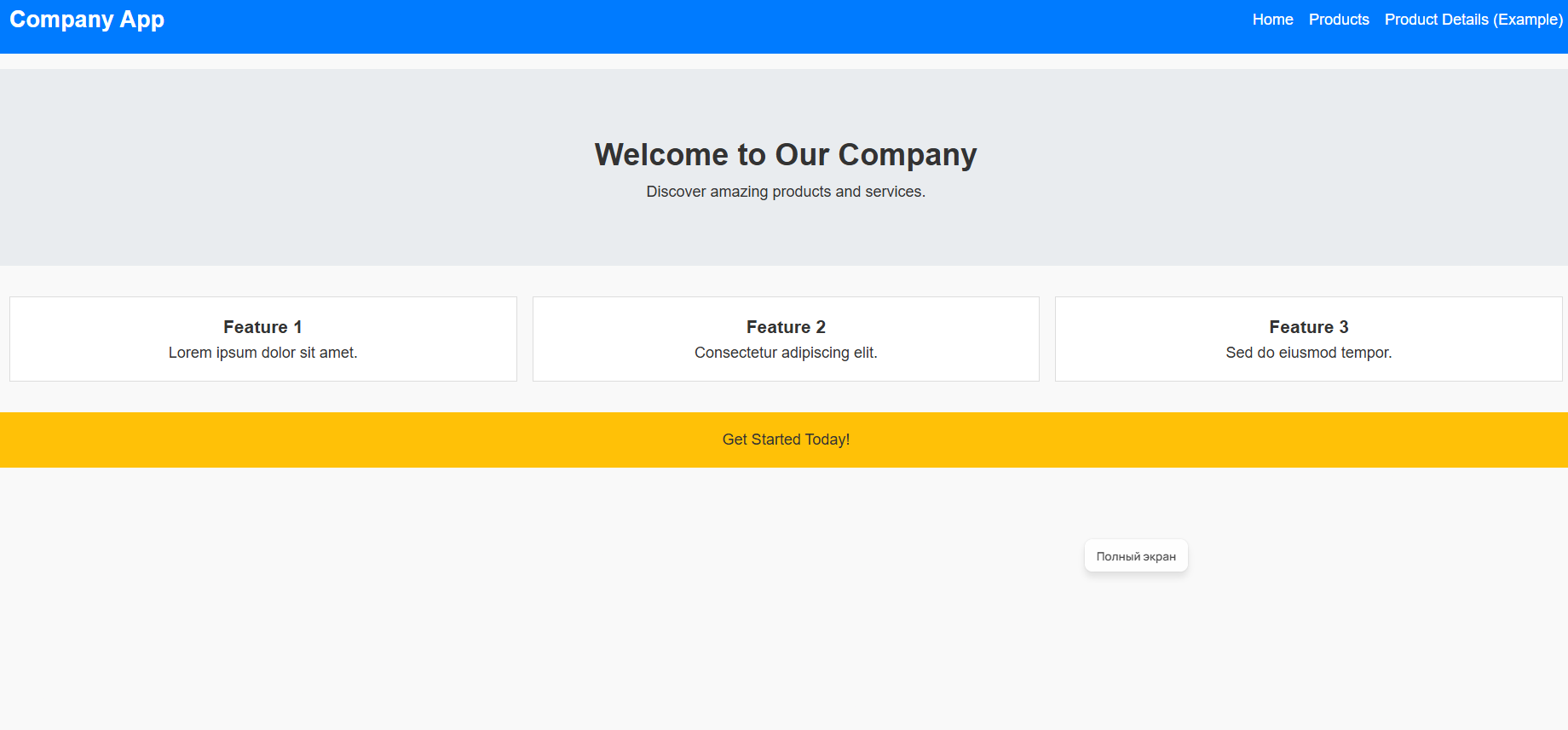
Модель проанализирует визуальную структуру наброска, определит ключевые блоки (шапка, меню, основной контент, подвал), распознает текстовые метки и сгенерирует готовый код. Это позволяет мгновенно создать рабочий прототип, который раньше требовал бы нескольких часов ручной верстки. Посмотрите полный ответ модели в этом чате.
Мультимодальный ИИ может «читать» визуальные данные, такие как:
Пример запроса: загрузите изображение графика продаж и таблицу с данными о рекламных кампаниях за последний квартал. После этого попросите ИИ:
«Найди ключевые тенденции, определи самый успешный месяц и предложи возможные причины роста или падения продаж».
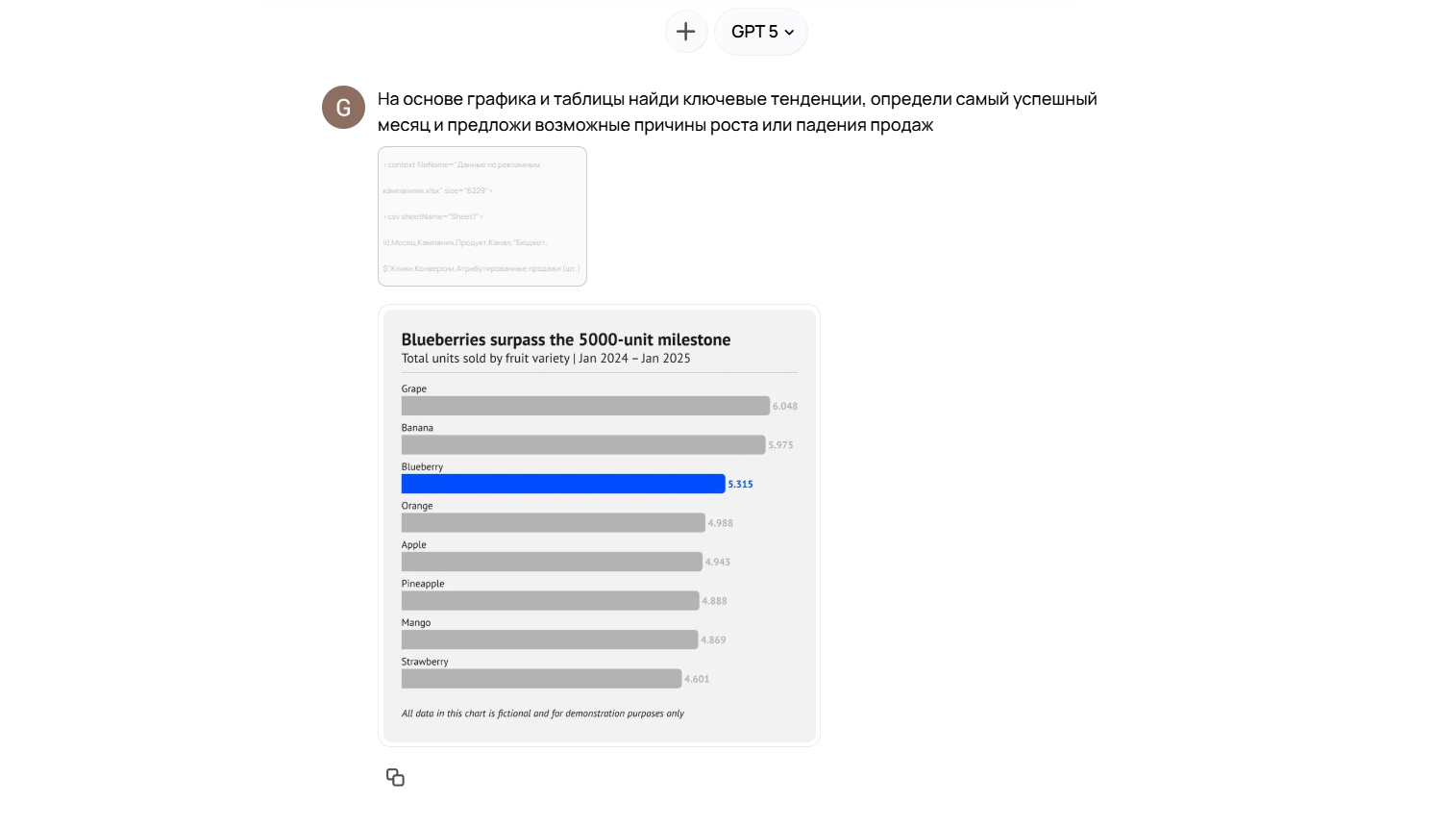
Нейросеть, например ChatGPT-5, извлекает числовые данные и текстовые метки из диаграмм, таблиц и инфографики, формируя сводный анализ. Это избавляет аналитиков от необходимости вручную переносить данные из изображений или PDF-отчетов, экономя часы работы и снижая риск ошибок при вводе. Посмотрите полный ответ модели в этом чате.
Студенты и исследователи могут использовать мультимодальный ИИ для изучения учебных материалов. Модели способны анализировать рукописные конспекты, схемы и диаграммы из учебников.
Пример запроса: сфотографируйте рукописную схему из лекции и загрузите изображение с промптом:
«Преобразуй эту схему в структурированный конспект на русском для подготовки к экзамену. Выдели ключевые термины и подготовь три вопроса для самопроверки».

Модель распознает рукописный текст и визуальные связи между блоками, после чего преобразует нелинейную информацию в логичный и последовательный текст. Это превращает статические заметки в интерактивный учебный инструмент и значительно ускоряет процесс повторения материала. Посмотрите полный ответ модели в этом чате.
Платформа GPTunneL предоставляет доступ к передовым мультимодальным нейросетям, каждая из которых обладает своими уникальными преимуществами. Выбор модели зависит от ваших задач — креативности, точности анализа, безопасности или конфиденциальности.
Вот 4 лидера рынка:
Эти платформы предлагают широкий спектр возможностей для решения бизнес-задач. Давайте рассмотрим каждую из них подробнее.
ChatGPT — это семейство универсальных диалоговых ИИ от OpenAI. Модель GPT-5 может анализировать содержимое фотографий, диаграмм и документов — например, вы можете загрузить изображение и задать по нему вопросы, попросить описать его или извлечь текст.
ChatGPT способен интерпретировать графики и таблицы, представленные в виде изображений, помогая выявлять тенденции без ручной обработки данных.
Сильные стороны ChatGPT:
Вы можете показать модели скриншот интерфейса и попросить написать код, который воспроизведет этот дизайн. Также, можно загрузить фотографию блюда и получить рецепт на его основе.
Sonar и Sonar Pro от Perplexity подходит к мультимодальности с позиции исследователя. Они анализируют код, изображения, текст или файлы и обогащают ответ самой актуальной информацией из интернета, обязательно указывая источники.
Например, вы можете загрузить фотографию нового, только что анонсированного гаджета или прототипа автомобиля, увиденного на выставке. По вашему запросу Sonar найдет последние новости об анонсе, предоставит официальные технические характеристики (цену, дату выхода, спецификации), процитирует первые обзоры и даст ссылки на статьи и сайт производителя, откуда была взята информация
Сильные стороны Sonar:
В то время как другие модели описывают то, что «видят», основываясь на своих обучающих данных, Sonar использует изображение как отправную точку для полноценного поиска и фактчекинга в реальном времени.
Claude отлично справляется с анализом PDF-файлов, отчетов, картинок и презентаций. Модель Claude 4.5 Sonnet может извлекать данные из таблиц и диаграмм, сохраняя при этом понимание общего контекста. Компания Anthropic уделяет большое внимание этике и безопасности, стремясь минимизировать генерацию вредоносного или предвзятого контента — это важно для корпоративного использования, где ошибка может иметь серьезные последствия.
Сильные стороны Claude:
Модель также известна способностью поддерживать длинные контексты без потери качества, что делает ее идеальной для работы с объемными отчетами, контрактами или научными статьями.
Grok от xAI способен обрабатывать текст, код, таблицы, а также анализировать широкий спектр визуальной информации, включая:
Например, Grok 4 может отвечать на вопросы о содержимом изображений и объединять визуальные данные с текстовыми запросами. Особенность нейросети — демонстрация хороших результатов в задачах, требующих пространственного мышления. Например, модель может объяснить логику работы механизма по его изображению.
Сильные стороны модели — преобразование визуальной информации в код, решение логических задач на основе изображений и создание креативных описаний с характерным стилем.
Мультимодальный ИИ — это мощный инструмент для бизнеса, который позволяет решать задачи быстрее, точнее и креативнее. Он стирает границы между разрозненными источниками данных, приближая взаимодействие с машиной к человеческому общению. Начните с простого: определите одну задачу в вашем бизнесе, которая требует анализа. Задайтесь вопросами:
Проведите небольшой эксперимент в GPTunneL, посмотрите на результат и развивайте то, что сработало лучше всего.



